Wer KI verlässlich nutzen will, muss zuerst klären, welches Wissen gelten soll.
Diese Erkenntnis stand am Anfang unserer Arbeit mit Linda, unserer lokalen KI-Assistentin für inside. Linda soll Fragen zu inside beantworten. Nicht aus allgemeinem Modellwissen. Nicht aus Vermutungen. Sondern auf Basis des inside Kompendiums.
Das klingt zunächst nach einem technischen Projekt. Tatsächlich wurde es vor allem ein Projekt über Wissensarbeit.
Denn schnell wurde klar: Eine KI braucht nicht einfach mehr Inhalte. Sie braucht gut strukturiertes, eingeordnetes und überprüfbares Wissen.
Das inside Kompendium als Ausgangspunkt
Das inside Kompendium ist unser Handbuch für Wissensarbeit mit inside.
Es beschreibt, wie Wissensmanagement in Unternehmen und Organisationen praktisch umgesetzt werden kann: mit klaren Begriffen, Rollen, Methoden, Prinzipien und Zusammenhängen.
Für Menschen war dieses Kompendium bereits hilfreich. Menschen können längere Texte lesen, Zusammenhänge selbst herstellen und fehlenden Kontext gedanklich ergänzen.
Für eine KI reicht das nicht.
Eine KI arbeitet nicht mit einem ganzen Handbuch im Kopf. Sie erhält zu einer Frage ausgewählte Ausschnitte als Kontext. Deshalb muss jeder Ausschnitt möglichst klar sein.
- Was ist die Aussage?
- Wofür gilt sie?
- In welchem Zusammenhang steht sie?
- Welche Frage kann sie beantworten?
Aus dem Kompendium wurde damit eine Wissensbasis.
Sections: Wissen in klare Einheiten schneiden
Der erste wichtige Schritt war die Segmentierung.
Wir haben das Kompendium in Sections gegliedert. Eine Section ist nicht einfach ein Absatz. Sie ist eine fachliche Einheit mit einer klaren Aufgabe im Kapitel.
Eine Section kann zum Beispiel erklären:
- warum ein Thema wichtig ist,
- was ein Begriff bedeutet,
- wie ein Zusammenhang funktioniert,
- welche Rolle ein Element im Wissensfluss spielt,
- welche typischen Fehler entstehen,
- welche Reflexionsfrage beim Übertragen in die eigene Praxis hilft.
Diese Gliederung war keine reine Formatfrage. Sie wurde zur Qualitätsprüfung.
Denn beim Schneiden wurde sichtbar, wo Inhalte noch zu viel auf einmal wollten. Manche Abschnitte erklärten mehrere Gedanken gleichzeitig. Manche Begriffe wurden verwendet, aber nicht sauber eingeführt. Manche Zusammenhänge waren für Menschen verständlich, aber für sich allein nicht klar genug.
Für Linda war genau das entscheidend.
Wenn eine Section später als Kontext für eine Antwort genutzt wird, muss sie stabil genug sein, um auch außerhalb des gesamten Kapitels Sinn zu ergeben.
Der inside Knowledge Stack als Koordinatensystem
Im nächsten Schritt haben wir die Inhalte im inside Knowledge Stack verortet.
Der inside Knowledge Stack beschreibt, wie Wissen in inside gedacht und gestaltet wird. Er zeigt, auf welchen Ebenen Wissen entsteht, geordnet wird, in Zusammenarbeit wirkt und zu Entscheidungen führt.
Wir unterscheiden sechs Ebenen:
- Wissen und Information
- Semantic Layer
- Governance und Standards
- Zusammenarbeit und Kultur
- Wirkung und Entwicklung
- Ökosystem und Rollen
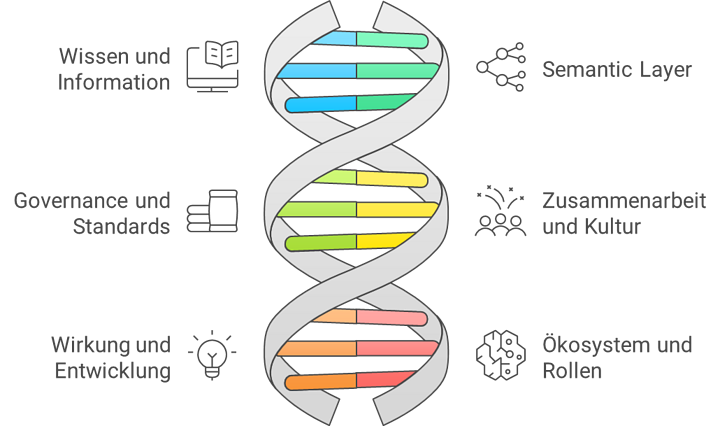
Diese Ebenen helfen, Wissen nicht nur thematisch, sondern funktional einzuordnen.
Das ist wichtig, weil ein Begriff je nach Zusammenhang eine andere Bedeutung haben kann.
Ein Beispiel:
Die Frage „Was ist eine Domain?“ kann sich auf unterschiedliche Dinge beziehen.
Geht es um ein abgegrenztes Wissensgebiet?
Geht es um Zugriff und Freigabe?
Geht es um Zusammenarbeit im Team?
Geht es um Rollen und Verantwortung?
Für Menschen ist diese Unterscheidung oft selbstverständlich. Für eine KI nicht.
Deshalb braucht Linda Hinweise, in welchem Bedeutungsraum sie suchen soll.
Der Knowledge Stack gibt dem Kompendium solche Koordinaten.
Embeddings und Vektorkarte
Damit Linda passende Inhalte finden kann, werden die Sections als Embeddings gespeichert.
Ein Embedding ist ein Bedeutungsprofil eines Textes. Dieses Profil wird durch ein Embedding-Modell erzeugt. Es besteht aus vielen Zahlenwerten und beschreibt Muster von Bedeutung, Kontext und Verwendung.
Texte mit ähnlicher Bedeutung erhalten ähnliche Bedeutungsprofile. Diese Profile können in einem Vektorraum miteinander verglichen werden. So lässt sich berechnen, welche Sections einer Frage semantisch nahe stehen.
Unsere Vektorkarte macht diesen Raum sichtbar.
Sie zeigt nicht das Kompendium als Inhaltsverzeichnis. Sie zeigt auch nicht die Kapitelstruktur. Sie zeigt Nähe, Distanz und Cluster.
Damit konnten wir sehen:
Welche Sections liegen fachlich nah beieinander?
Welche Inhalte bilden klare Gruppen?
Welche Kapitel sind gut verortet?
Welche Semantic Groups überlagern sich?
Welche Inhalte stehen isoliert?
Die Vektorkarte ist keine absolute Wahrheit. Sie ist eine Projektion eines komplexen Bedeutungsraums in eine sichtbare Ansicht.
Aber sie wurde für uns zu einem wichtigen redaktionellen Werkzeug.
Denn isolierte Punkte werfen Fragen auf:
Ist dieser Inhalt wirklich ein Sonderfall?
Ist er zu allgemein formuliert?
Vermischt er mehrere Gedanken?
Fehlt ein verbindender Begriff?
Oder fehlt im Kompendium noch ein erklärender Zwischenschritt?
So wurde die Vektorkarte zum Spiegel der Wissensbasis.
Die Frage bekommt einen Ort
Nicht nur die Sections können als Bedeutungsprofile dargestellt werden. Auch eine Frage kann so eingeordnet werden.
In unserer Vektorkarte markieren wir eine konkrete Frage mit einem Stern.
Der Stern zeigt, wo die Frage im Wissensraum des inside Kompendiums landet.
Das hilft bei der Prüfung:
Liegt die Frage nahe bei passenden Sections?
Berührt sie die richtige Semantic Group?
Gehört sie zum erwarteten Kapitel?
Oder landet sie in einem Bereich, der nur sprachlich ähnlich klingt, aber fachlich nicht passt?
Dieser Schritt ist wichtig, weil Retrieval nicht nur Wortähnlichkeit sein darf. Linda soll nicht einfach irgendetwas Ähnliches finden. Sie soll den passenden Kontext finden.
Intent-Erkennung: Welche Art von Antwort wird gesucht?
Ein weiterer wichtiger Schritt ist die Intent-Erkennung.
Intent bedeutet: Welche Frageabsicht steckt in einer Frage? Nicht jede Frage sucht dieselbe Art von Wissen.
„Was ist eine Domain?“ sucht vermutlich eine Definition.
„Warum sind Domains wichtig?“ sucht eine Begründung.
„Wie lege ich eine Domain sinnvoll an?“ sucht ein Vorgehen.
„Welche Verantwortung haben Domain-Manager?“ sucht eine Rollenperspektive.
Die Begriffe können ähnlich sein. Die erwartete Antwort ist aber eine andere. Deshalb reicht es nicht, nur semantisch ähnliche Sections zu finden. Linda muss auch wissen, welche Art von Kontext für die Antwort gebraucht wird.
Eine Definition braucht andere Sections als eine Handlungsanleitung.
Eine Reflexionsfrage braucht andere Wissenseinheiten als eine Navigationsfrage.
Eine strategische Einordnung braucht andere Zusammenhänge als eine kurze Begriffsklärung.
Intent-Erkennung hilft, die Suche gezielter zu steuern.
Prompt + Kontext = Antwort
Am Ende entsteht Lindas Antwort aus zwei Bausteinen:
Prompt + Kontext = Antwort.
Der Prompt ist die Arbeitsanweisung.
Er legt fest:
welche Rolle Linda hat,
wie sie antworten soll,
welche Grenzen gelten,
welche Quellen sie nutzen darf,
was passieren soll, wenn Kontext fehlt.
Der Kontext ist das gefundene Wissen.
Bei Linda kommt dieser Kontext aus dem inside Kompendium. Es sind die Sections, die zur Frage passen und den Antwortkontext bilden.
Ohne Kontext würde Linda nur sprachlich plausible Antworten erzeugen.
Ohne Prompt hätte Linda zwar Material, aber keine klaren Regeln.
Erst beides zusammen macht die Antwort kontrollierbar.
Das ist der entscheidende Unterschied zwischen einer beeindruckenden und einer belastbaren KI-Antwort.
Beeindruckend ist, wenn eine Antwort gut klingt.
Belastbar ist, wenn klar ist, worauf sie sich stützt.
Die Grenze als Qualitätsmerkmal
Ein zentraler Teil unserer Arbeit war die Frage:
Was soll Linda tun, wenn kein ausreichender Kontext gefunden wird?
Unsere Antwort ist klar:
Dann soll Linda keine Antwort erfinden.
Sie soll sichtbar machen, dass der Kontext fehlt.
Zum Beispiel:
„Dazu liegt im Kompendium kein ausreichender Kontext vor.“
Das klingt unspektakulär. Für Wissensmanagement ist es aber entscheidend.
Denn in Organisationen ist nicht jede plausible Antwort auch eine gültige Antwort.
Eine verlässliche KI muss deshalb nicht nur gut antworten. Sie muss auch wissen, wann sie nicht antworten darf.
Genau hier zeigt sich der Wert einer strukturierten Wissensbasis. Jede unbeantwortete Frage wird zu einem Hinweis:
Fehlt ein Begriff?
Fehlt ein Zusammenhang?
Fehlt ein Beispiel?
Fehlt eine Rollenperspektive?
Oder ist der Inhalt vorhanden, aber nicht gut genug strukturiert?
So wird Linda nicht nur zur Assistentin. Sie wird auch zum Werkzeug für die Weiterentwicklung des Kompendiums.
Open Source als nächster Schritt
Das Projekt soll Open Source werden.
Geplant sind:
die Rails-App,
der Embedding-Service,
der RAG-Service,
das Docker-Setup.
Nicht als fertige Wunderlösung. Sondern als Werkzeug, Lernweg und Einladung.
Unser Ziel ist es, sichtbar zu machen, wie Organisationen ihr eigenes Wissen so aufbereiten können, dass KI damit verlässlich arbeiten kann.
Denn KI-Readiness beginnt nicht bei der KI. Sie beginnt bei der Qualität des eigenen Wissens.
Fazit
Linda ist für uns mehr als eine lokale KI-Assistentin. Sie ist ein Prüfstein für Wissensarbeit. Sie zeigt, wo Begriffe klar sind. Wo Kontext fehlt. Wo Wissen gut verbunden ist. Und wo das Kompendium weiterentwickelt werden muss.
Unsere wichtigste Erkenntnis lautet:
KI macht Wissensmanagement nicht überflüssig.
KI macht sichtbar, ob Wissensmanagement funktioniert.